
The $2M Discovery Disaster: Why Your CMDB is a Liability, Not an Asset
- SnowGeek Solutions
- Mar 20
- 5 min read

I have witnessed firsthand the wreckage of a $2 million ServiceNow ITOM implementation failure. It wasn’t a lack of budget that killed it, nor was it a lack of talent. It was the slow, agonizing accumulation of "Technical Scar Tissue": the result of cutting corners during the Discovery phase until the platform eventually buckled under its own weight.
In this first installment of my "Technical Scar Tissue" series, I want to pull back the curtain on a specific disaster recovery project I led. A global logistics firm had spent eighteen months and millions of dollars trying to stand up a "Single Source of Truth." Instead, they created a $2M liability that actively misled their Incident Management teams and eventually crashed their production instance.
If you are currently navigating a ServiceNow ITOM implementation, this post is your warning and your roadmap.
The Anatomy of a Failure: 5 MID Servers and a World of Pain
When I was brought in as the Lead Architect to perform a "post-mortem" on their CMDB, the health score was sitting at a dismal 14%. The primary culprit? A fundamental misunderstanding of MID Server orchestration.
The previous implementation team had deployed five MID Servers across their global data centers. On the surface, this sounds like a standard high-availability setup. However, the configuration was a nightmare. They had configured these MID Servers with overlapping IP ranges.
In ServiceNow Discovery, if your IP Address Ranges are not strictly defined and segmented, multiple MID Servers will attempt to "claim" the same device. This resulted in a catastrophic duplication of Configuration Items (CIs). We found over 45,000 duplicate Linux Server records. Every time a discovery schedule ran, the Identification and Reconciliation Engine (IRE) struggled to match the incoming data with the existing mess.
Instead of a streamlined asset map, the client had a digital graveyard. When an incident occurred on "Server-App-01," the service desk saw six different versions of that server. This drove their Mean Time to Repair (MTTR) through the roof, as engineers wasted hours trying to figure out which CI was the "real" one.
The Day the Instance Stood Still: SNMP Trap Flooding
The "Disaster" reached its zenith during a routine network scan. The team had enabled SNMP Trap listeners on all MID servers without implementing any filtering or throttling at the source or within the ServiceNow Event Management layer.
As they scanned a legacy subnet, a series of misconfigured switches began firing SNMP traps in a recursive loop. Thousands of events per second flooded the MID Servers, which faithfully passed them up to the ServiceNow instance. The sheer volume of incoming noise overwhelmed the ECC (External Communication Channel) Queue.
The production instance, unable to process the backlog of events while simultaneously trying to manage standard ITSM traffic, effectively locked up. For four hours, one of the world’s largest logistics providers was blind. No incidents could be logged, no changes approved, and no assets tracked.
This is the hidden cost of ServiceNow ITOM implementation failures: it isn't just the software licensing; it’s the operational paralysis that occurs when the tool meant to provide clarity becomes the source of the chaos.

The Turning Point: Implementing the 'Cleanroom' Discovery Strategy
To salvage the $2M investment, I had to do more than just delete duplicate records. We needed a fundamental architectural shift. I introduced what I call the 'Cleanroom' Discovery Architecture.
In a "Cleanroom" approach, we treat the CMDB as a high-security vault rather than a public park. We don't let Discovery dump data directly into the production tables without a rigorous validation layer.
The Cleanroom Discovery Architecture (Technical Description)
Imagine a three-tier architecture:
The Collection Layer: MID Servers are strictly segmented by VLAN and IP range. No overlaps. We implemented "Capability" tags so that only specific MID servers could handle sensitive protocols like SNMP or WMI.
The Validation Layer (The Cleanroom): Instead of writing directly to the cmdb_ci tables, we utilized a staging area. We leveraged the ServiceNow Identification and Reconciliation Engine (IRE) with custom-built "Pre-Import" scripts. These scripts checked for naming convention compliance and verified against the IT Asset Management (ITAM) "Expected Inventory" before a CI was ever created.
The Production Layer: Only validated, "Clean" CIs are promoted to the active CMDB. This ensures that the data used by Change and Incident Management is 100% trustworthy.
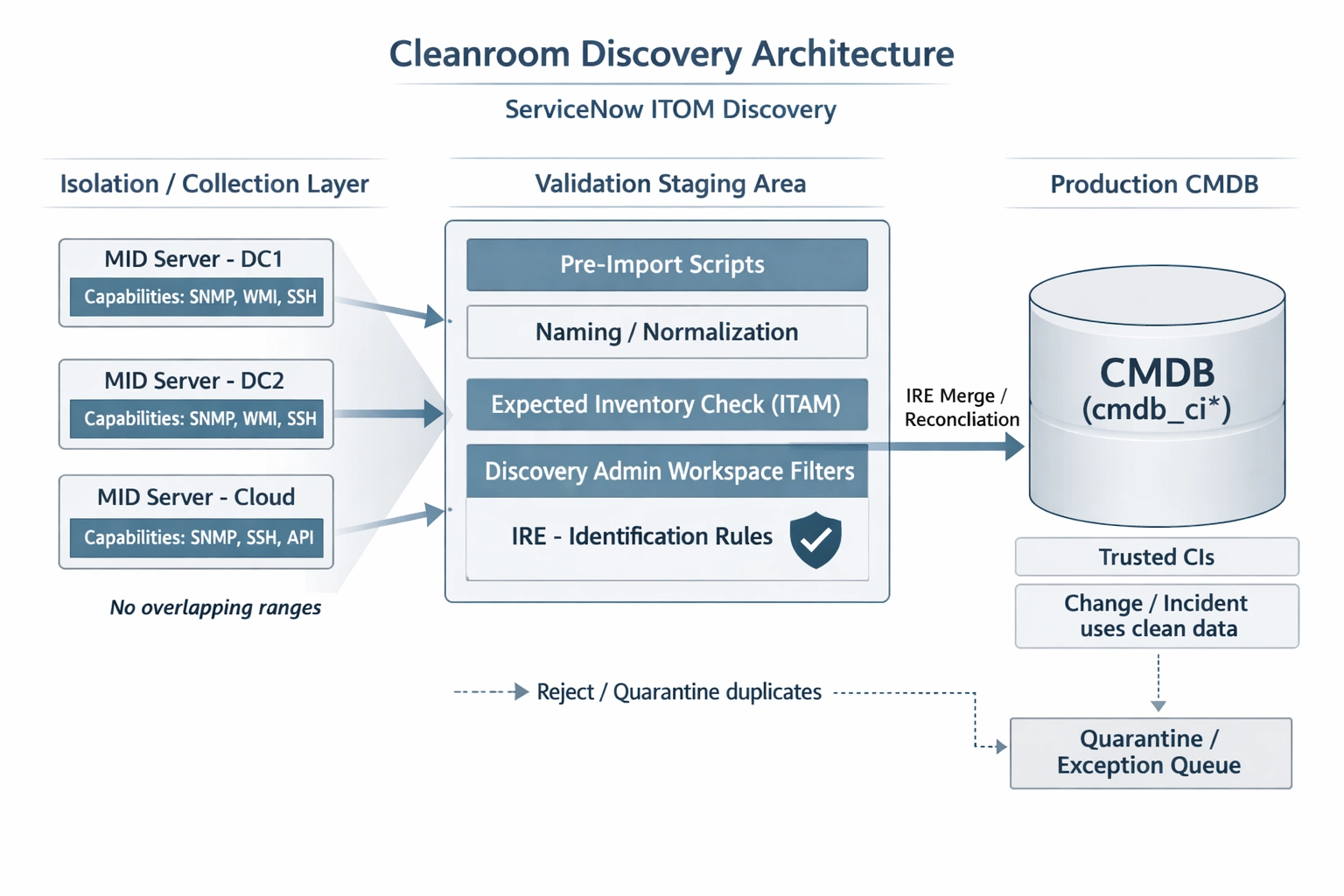
Cleanroom Discovery Architecture: Isolation (segmented MID Servers) → Validation Staging Area (pre-import scripts, normalization, ITAM expected inventory checks, Discovery Admin Workspace filters) → IRE merge/reconciliation → Production CMDB (trusted CIs), with a quarantine path for duplicates/exceptions.
Mastering the IRE: The Secret to Platform Health
The most transformative step in this recovery was the precision-tuning of the IRE rules. Many organizations leave these at the "out-of-the-box" (OOB) settings, which is a recipe for disaster in complex environments.
In the Washington and Xanadu releases, ServiceNow has significantly enhanced the Discovery Admin Workspace. I utilized these new features to visualize identification overlaps before they happened. We moved away from simple "Name" or "Serial Number" matching. We implemented multi-source identification rules that prioritized data from the ServiceNow Service Graph Connectors over generic Discovery probes.
According to the latest WorkArena Benchmarks, organizations that utilize structured IRE and Service Graph Connectors see a 40% improvement in CMDB data accuracy within the first six months. By applying these metrics, we moved the client's health score from 14% to 92% in just one fiscal quarter.
From Liability to Asset: The Results
Once the "Cleanroom" was in place and the MID servers were properly orchestrated, the results were transformative.
Cost Reduction: We decommissioned redundant monitoring tools that were no longer needed once Discovery was reliable, saving $300k in annual licensing.
Operational Excellence: MTTR dropped by 22% because technicians finally trusted the dependency maps.
Strategic Foresight: With a clean CMDB, the client could finally use ServiceNow ITBM (Strategic Portfolio Management) to accurately forecast infrastructure spend for 2027.
The $2M disaster was eventually mitigated, but the "Technical Scar Tissue" remained a reminder of why precision matters. A CMDB is not a database; it is a living, breathing map of your business's nervous system. If you treat it like a dump, it will act like one.

Is Your Discovery Strategy Creating Scar Tissue?
The transition from a failing ITOM implementation to a high-performing asset demands expert guidance and strategic foresight. Don’t wait for your instance to crash during a network scan to realize your MID servers are misconfigured.
At SnowGeek Solutions, we specialize exclusively in ServiceNow. We don't just "install" modules; we architect solutions that scale. Whether you are struggling with duplicate CIs or looking to elevate your platform to the Xanadu release standards, I will guide you through the essential steps to maximize your platform's potential.
Your Next Steps:
Stop the Bleeding:Visit our contact page at snowgeeksolutions.com and share your project details. Let’s conduct a platform health audit before your next major scan.
Stay Ahead:Register with SnowGeek Solutions to receive platform updates, expert insights, and more entries in our 'Technical Scar Tissue' series.
About the Author: James Snow
James Snow is a Senior ServiceNow Architect and the Lead Consultant at SnowGeek Solutions. With over 15 years of experience across the ServiceNow ecosystem, James has led some of the most complex ITOM and ITSM transformations in the Fortune 500. He specializes in "Platform Rescue" missions, helping organizations turn failing, high-debt implementations into streamlined, value-driving assets. When he isn't debugging complex IRE payloads, James contributes to the ServiceNow Community and mentors the next generation of platform architects.
For more information on implementation best practices, check out our Ultimate Guide to ServiceNow Implementation Success in 2026.
Comments